共同研究プロジェクト「テクストアナリティクスとデジタルヒューマニティーズ」研究会 · 2026年6月12日(金)
itak
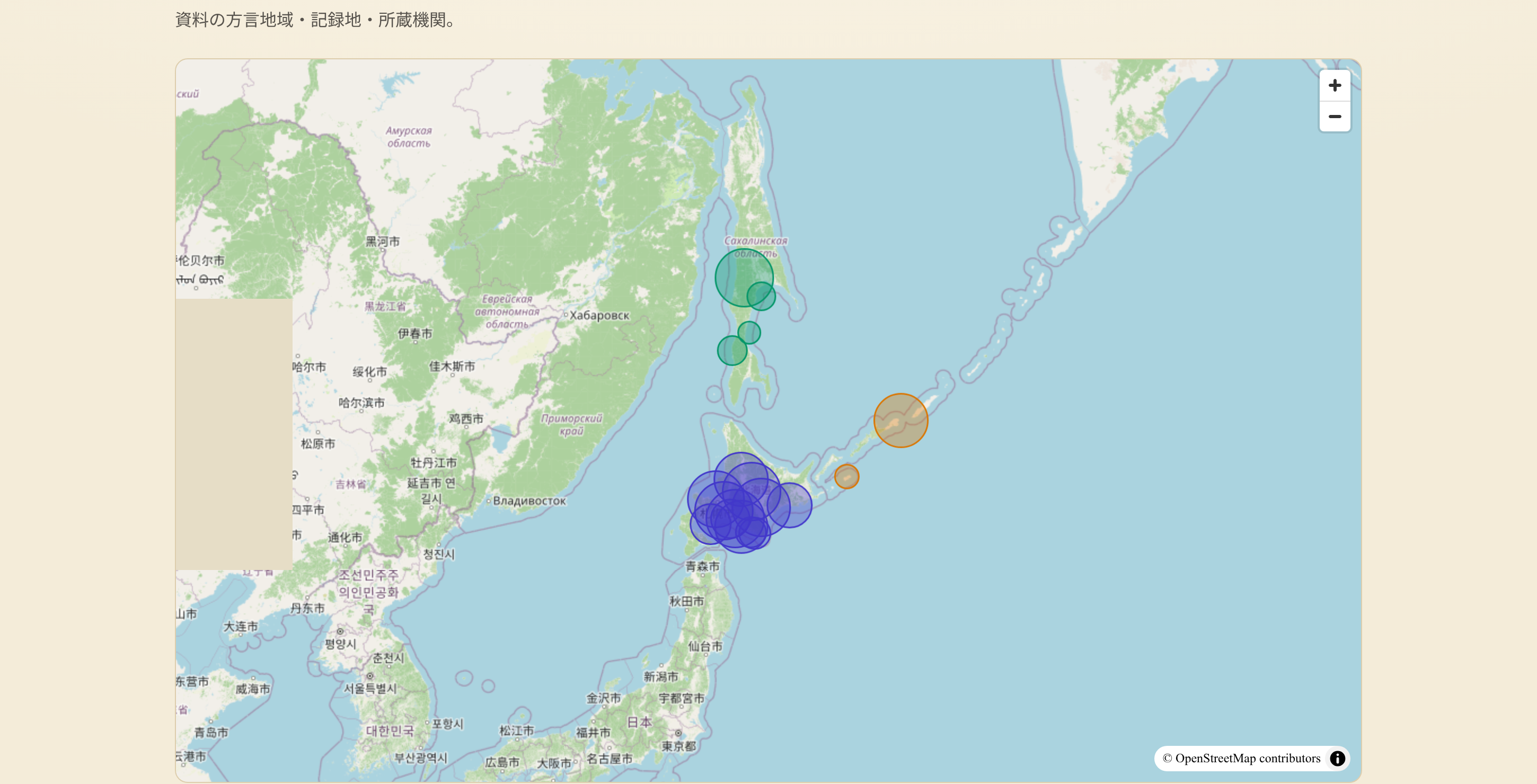
イタㇰ
アイヌ語資源とLLMをつなぐ
RAGによる低資源言語研究基盤の構築と運用

于 拙(う せつ)字 朴之(ぼくし)Yo, Cjyet
大阪大学大学院人文学研究科 言語文化学専攻 博士後期課程二年
https://researchmap.jp/yocjyet / contact@yocjyet.dev